典型回答 Spring Cloud是基于Spring Boot的分布式系统开发工具,它提供了一系列开箱即用的、针对分布式系统开发的特性和组件,用于帮助开发人员快速构建和管理云原生应用程序。
Spring Cloud的主要目标是解决分布式系统中的常见问题,例如服务发现、负载均衡、配置管理、断路器、消息总线等。
所以,单体应用使用Spring,需要快速构建,简化开发使用SpringBoot,构建分布式、微服务应用,使用SpringCloud。
下图是我画的一张SpringCloud中核心组件起到的作用以及所处的位置:
(图片可放大查看)
下面是Spring Cloud常用的一些组件:
Eureka:服务发现和注册中心,可以帮助服务消费者自动发现和调用服务提供者。 Ribbon:负载均衡组件,可以帮助客户端在多个服务提供者之间进行负载均衡。 ✅Ribbon是怎么做负载均衡的?
OpenFeign:声明式HTTP客户端,可以帮助开发人员更容易地编写HTTP调用代码。 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 [✅OpenFeign 不支持了怎么办?](https://www.yuque.com/hollis666/ec96i7/itmcpq5517975ttq) 4. Hystrix:断路器组件,可以帮助应用程序处理服务故障和延迟问题。 [✅Hystrix和Sentinel的区别是什么?](https://www.yuque.com/hollis666/ec96i7/gvgtod53vvivtk0t) 5. ~~Zuul:API网关,可以帮助应用程序处理API请求的路由、负载均衡、安全和监控等问题。~~ [✅Zuul、Gateway和Nginx有什么区别?](https://www.yuque.com/hollis666/ec96i7/uliggwanbo7t3hxg) 6. Config:分布式配置管理组件,可以帮助应用程序从远程配置源获取配置信息。 7. Bus:消息总线组件,可以帮助应用程序实现分布式事件传递和消息广播。 8. Sleuth:Sleuth是Spring Cloud生态系统中的一个分布式追踪解决方案,可以帮助开发人员实现对分布式系统中请求链路的追踪和监控。 9. Gateway:spring Cloud Gateway是Spring Cloud推出的第二代网关框架,取代Zuul网关。提供了路由转发、权限校验、限流控制等作用。 [✅为什么需要SpringCloud Gateway,他起到了什么作用?](https://www.yuque.com/hollis666/ec96i7/ow7cnpaa2du8zvv5) 10. Security:用于简化 OAuth2 认证和资源保护。 但是,有的时候我们并不一定非要全部都用SpringCloud的这些组件,有的时候我们也可以选择其他的开源组件替代。比如经常用Dubbo/gRPC来代替Feign进行服务间调用。经常使用Nacos代替Config+Eureka来实现服务发现/注册及配置中心的功能。 如下图是我[项目课中的技术栈](https://www.yuque.com/hollis666/ec96i7/dgolk0cckpb94sia),目前比较主流的SpringCloud的架构: 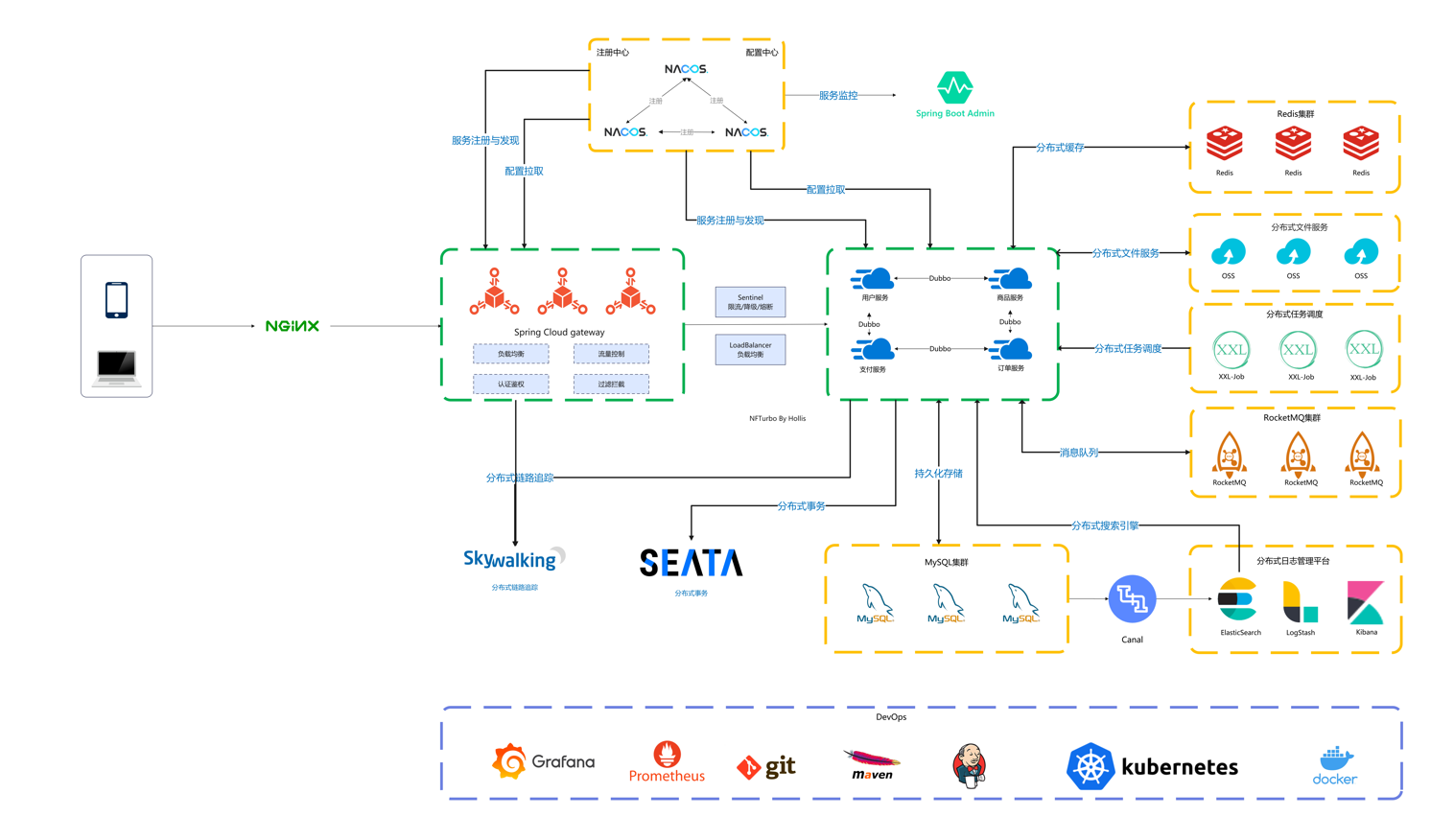 # 扩展知识 ## <font style="color:rgb(52, 53, 65);">Spring Cloud Alibaba</font> Spring Cloud Alibaba则是由Alibaba推出的分布式开发框架,它主要针对于微服务和云原生应用的开发和部署。Spring Cloud Alibaba提供了一系列的组件和解决方案,例如服务注册、配置管理、消息驱动等。Spring Cloud Alibaba的组件通常基于阿里巴巴自研的组件,例如Nacos、Sentinel、RocketMQ等。 依托 Spring Cloud Alibaba,您只需要添加一些注解和少量配置,就可以将 Spring Cloud 应用接入阿里分布式应用解决方案,通过阿里中间件来迅速搭建分布式应用系统。 目前 Spring Cloud Alibaba 提供了如下功能: 1. 服务限流降级:支持 WebServlet、WebFlux, OpenFeign、RestTemplate、Dubbo 限流降级功能的接入,可以在运行时通过控制台实时修改限流降级规则,还支持查看限流降级 Metrics 监控。 2. 服务注册与发现:适配 Spring Cloud 服务注册与发现标准,默认集成了 Ribbon 的支持。 3. 分布式配置管理:支持分布式系统中的外部化配置,配置更改时自动刷新。 4. Rpc服务:扩展 Spring Cloud 客户端 RestTemplate 和 OpenFeign,支持调用 Dubbo RPC 服务 5. 消息驱动能力:基于 Spring Cloud Stream 为微服务应用构建消息驱动能力。 6. 分布式事务:使用 @GlobalTransactional 注解, 高效并且对业务零侵入地解决分布式事务问题。 7. 阿里云对象存储:阿里云提供的海量、安全、低成本、高可靠的云存储服务。支持在任何应用、任何时间、任何地点存储和访问任意类型的数据。 8. 分布式任务调度:提供秒级、精准、高可靠、高可用的定时(基于 Cron 表达式)任务调度服务。同时提供分布式的任务执行模型,如网格任务。网格任务支持海量子任务均匀分配到所有 Worker(schedulerx-client)上执行。 9. 阿里云短信服务:覆盖全球的短信服务,友好、高效、智能的互联化通讯能力,帮助企业迅速搭建客户触达通道。 ## <font style="color:rgb(52, 53, 65);">Spring Cloud Tencent</font> Spring Cloud Tencent 是腾讯开源的一站式微服务解决方案。 Spring Cloud Tencent 实现了Spring Cloud 标准微服务 SPI,开发者可以基于 Spring Cloud Tencent 快速开发 Spring Cloud 云原生分布式应用。 Spring Cloud Tencent提供的能力包括但不限于: 